The Art of Data Synthesis: A Closer Look
An introduction to synthetic data, machine learning methods of generation & it's role in data democratisation.


The moment I first set eyes on the term "Synthetic Data", I had two thoughts; this sounds like something out of an episode of Black Mirror, but this is most definitely about to become my next topical obsession in data science.
A dilemma exists in the data science world; 80% of a data scientists time can often be spent collecting, cleaning and reformatting large and often complex or fragmented datasets, which can leave less time than one would like to carry out analysis & derive insights. Having the ability to expand datasets, using machine learning techniques to generate high quality synthetic data, could make a world of difference in a data strategy sense! In the context of digital society, synthetic data contributes greatly to data democratisation, but more on this later- let's explore the concept.
Artificial Intelligence models are trained with datasets consisting of real, directly measured data, which typically have some expenses and restrictions attached to their generation such as privacy or nature of collection. For example, a simple classification model would train, validate and test well on a real dataset. However, this same model would become even more accurate if it had more data to train with right? Well, where direct measurement to expand a dataset is not a feasible option, we can turn to artificially generated data known as synthetic data. This data comes from rules, simulations, modelling and other techniques.
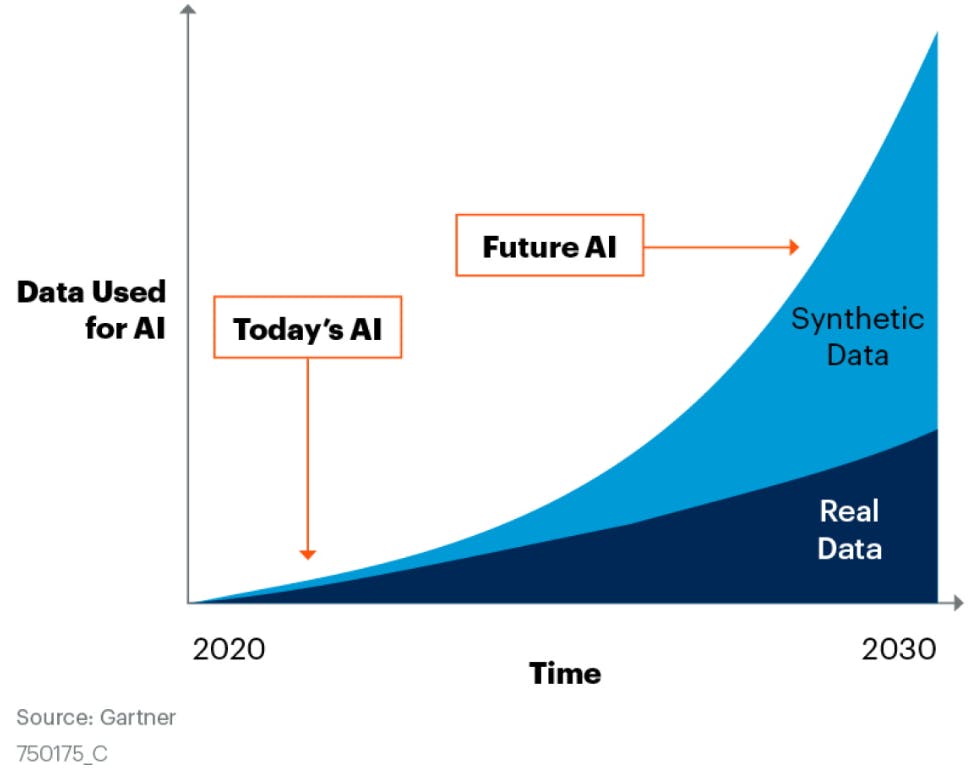
Figure 1.0: Chart of share of data used for AI over time. Source: Gartner, “Maverick Research: Forget About Your Real Data – Synthetic Data Is the Future of AI,” Leinar Ramos, Jitendra Subramanyam, 24 June 2021.*
A particular question I had when thinking about the generation of synthetic data, for which there are many different techniques, was what type of model would be suited to the job? Enter GANs; Generative Adversarial Networks. This is essentially a competition between two neural networks, a generator and a discriminator. The job of the generator is to create data that resembles closely the original data and the discriminator will classify the generated data. The generator network is attempting to eventually create artificial data that the discriminator will classify as real data. When this happens, the discriminator loss function will cause the discriminator to update its weighting of neurons in hidden layers of the network through the process of backpropagation.
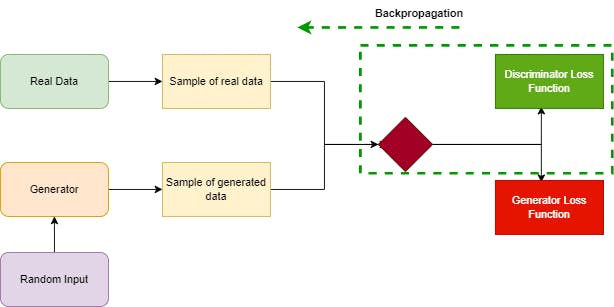
Figure 2.0: Recreated GAN diagram displaying backpropagation whilst the discriminator model is training.*
Backpropagation works in a slightly altered fashion for the training of the generator. The loss function of focus here is the generator loss function, so the impact of each weight on the output is the base for adjustment in the right direction. This impact is dependent on the impact of the weights of the discriminator. To summarise one iteration of training for the generator, the classification of the sample of generated data is used to calculate a loss and backpropagation occurs through both the discriminator and generator finding gradients, which are then used to change the weights of the generator.
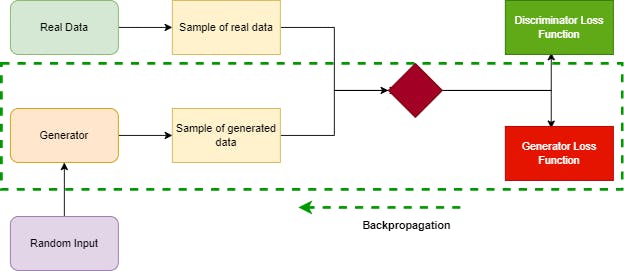
Figure 2.1: Recreated GAN diagram displaying backpropagation whilst the generator model is training.*
The training of the GAN is in phases where the discriminator and generator train alternatively, but either network is kept constant during the training phase of the other to allow the discriminator to identify the flaws in samples of generated data. Conversely, the discriminator remains constant as the generator trains so that the target of classification is technically always achievable for the generated data.
There are caveats with this form of training, however, in that as the generator improves, the ability of the discriminator to identify real from generated data will eventually diminish. In an ideal scenario for the generator, the discriminator network will be 50% accurate. This means that over time the outputs of the discriminator network will be less useful and could eventually become random and therefore low quality for training. On the bright side, it is important to note this is often only a temporary state for a GAN. If you'd like to read in much more detail about GANS, this post in the Google Developers blog contains comprehensive breakdowns of the machine learning concepts described here.
The fact that increasingly higher qualities of synthetic data can come into existence every day due to rapidly advancing machine learning techniques is exciting; the potential impact on fields like medical research can be very positive. Think of using synthetic data for the creation of control groups in clinical trials for rare diseases, where the volumes of existing data may be simply too low to create prediction models.
Combining real and synthetic data can accelerate the process of understanding problems around which we have limited availability of data, which ultimately reduces the time between uncovering findings from data and positively impacting lives. Synthesis can democratise data by removing limitations around access to safe, high quality, useable data which does not need to be guarded by an organisation. This is a big step in the right direction for data anonymisation and sharing processes, which are important building blocks for bringing data democratisation to life.